
We have laid out the following accounts for our core DSOP architecture:
- DSOP CodePipelines
- DSOP CodeCommit
- DSOP Tooling
Each of these provides us with different outcomes and tries to limit access to developers and ops. Traditionally, many would combine the CodeCommit and CodePipelines accounts into one. This is an ok strategy, but could potentially cause some issues with separation of duties. Our goal is to break that and enable CodeCommit and CodePipeline to reside in different accounts.
There are a lot of "Gotchas" in the process of developing Pipelines. For one, creating a pipeline that works on multiple branches is basically impossible with CodeCommit feeding directly into CodePipeline. You need a 1:1 pipeline for your branch. So, if you are using a branch development strategy, you will create a lot of pipelines. This becomes a tangled mess if you need to update those pipelines if they still exist.
Breaking our code into accounts for CodeCommit and CodePipeline, helped enable this. Our strategy follows below.
CodeCommit Account
When we roll out the CodeCommit account, we create a Lambda function that is the CodeCommit Code Publisher. This is a Container style Lambda Function. We had to use a Container, because you can't get the git tools within regular lambda from code. So, by using a Container, we can add the git tools and use our NodeJS code on top of that.
This Code Publisher function handles an event from any CodeCommit repo. From there, it clones the branch, zips up the branch, and sends it to an S3 bucket in the CodePipeline account.
Then, the Code Publisher starts the execution of the CodePipeline that maps to 1) the project name 2) the branch we are working on.
Within the CodePipeline account, per project, we create pipelines: 1) a production pipeline, 2) a QA pipeline, and 3) a feature pipeline.
If someone creates a branch feature/bananas we send that to the feature pipeline, if someone creates a qa/apples branch, it is sent to the qa pipeline, etc.
Now, if we need to update the pipelines, we can just update one core CloudFormation template, per project, and we are done. Doing the "create a pipeline per branch" could spawn into 10's or 100's of branches, depending how big your dev team is.
The workflow is as such:
- User does work and commits a branch to CodeCommit
- CodeCommit kicks off a notification to the CodeCommit Code Publisher Lambda Function
- The CodeCommit Code Publisher performs a
git cloneof the repo locally - The CodeCommit Code Publisher zips that directory
- The CodeCommit Code Publisher assumes a role in the CodePipeline account and sends the zip to the S3 bucket using the
project name+/+branch name.zipto S3 - The CodeCommit Code Publisher then invokes the Start Execution on the appropriate pipeline within the CodePipeline account.
Now, you can configure the CodePipeline account to listen for CloudTrail events for the object being uploaded to S3. We found this to be a headache and decided to add the permission to start execution to the role for the CodeCommit Code Publisher and allow it to perform the kickoff action. Done.
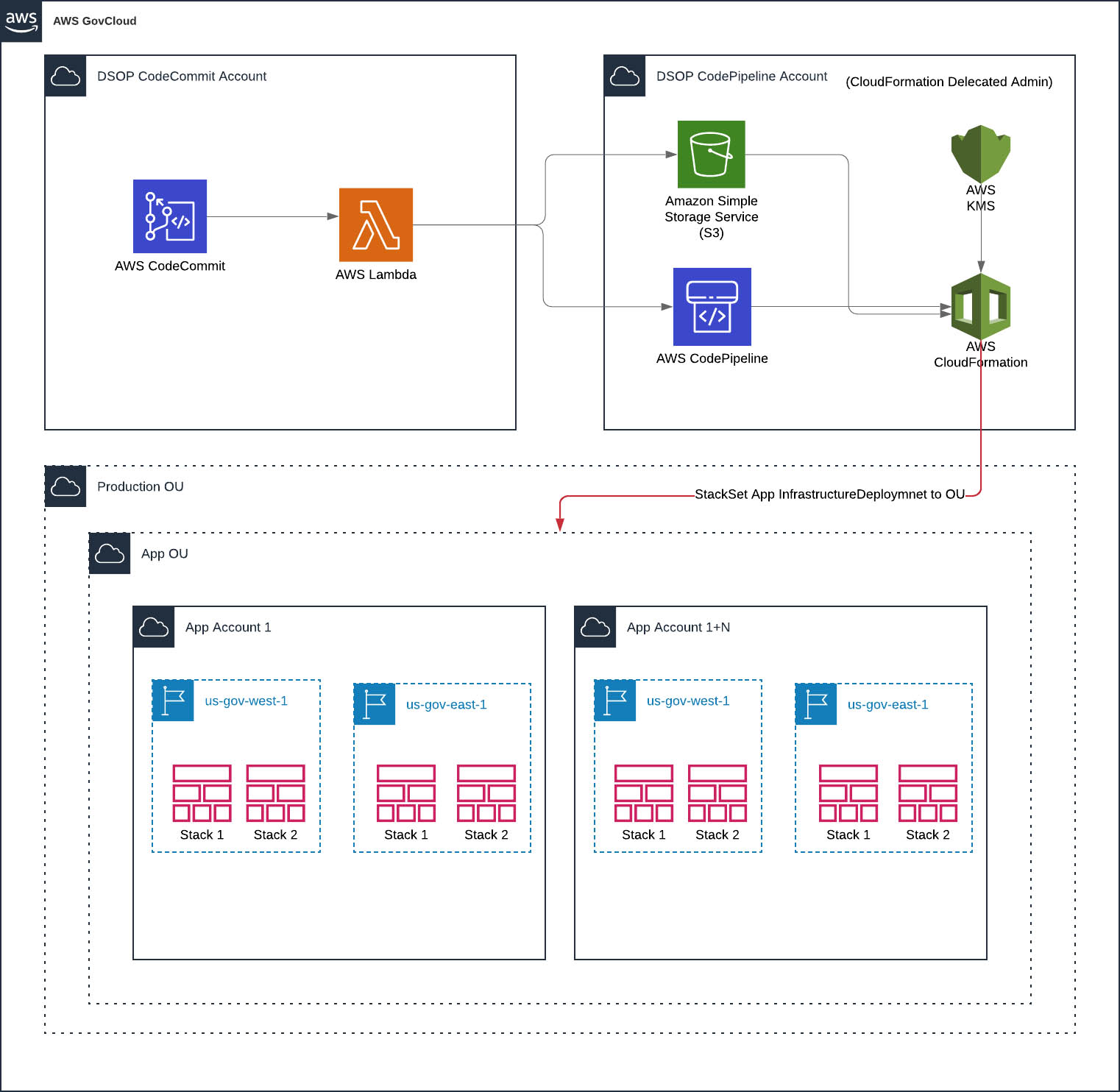
CodePipeline Account
The CodePipeline account is where the magic happen. We originally started with a CloudFormation template that had several child CloudFormation templates within it. Basically, we could configure the root template and indicate if it was a Server App, iOS, or Android and it would run the appropriate child templates. This quickly became unmanageable.
We then migrated to creating specific root CloudFormation template, that had:
- "core" template within it that would setup an ECR (if a server app), roles, CodeBuild configuration (if appropriate), permissions, etc that the pipelines could use
- "pipeline" template that takes in a type of pipeline branch, production/qa/feature. The type of branch would indicate what features of the pipeline we deploy.
For instance, in our "feature" pipeline, we only want to scan and build the code. We don't care at all about deploying (in this case). But, the QA branch, we want to deploy to a test account so we can perform some smoke testings. Thus, production we want to deploy to production.
So, we then deploy all three pipelines and let them do their magic.
The beauty of where this goes now is, we can configure CodePipeline to pull from a variety of sources as we want. We could leverage GitLab or GitHub as our source of code with very little modification.
AWS GitOps is lacking
I consider GitLab to be the gold standard of CI/CD, AWS missed the boat to buy them when they were a $1b company, it would have changed the portfolio for the better.
The Code* suite of apps is missing key tools like issue tracking, epics, etc. Until these are there, AWS GitOps is a decent tool for source control, CI/CD, deployment, but misses a slew of requisite tools to do modern software development.
Don't get me wrong, it all works and works just fine, it is just lacking some essential tooling for the modern age.
We do wish the Code* suite of tools had a bit better integration. A powerful aspect of AWS is you can build whatever you want, the downside is you end up building some Rube Goldberg machines to accomplish what you want.
Closing Thoughts
I just wanted to get some of these thoughts down as we iterate through leveraging CodePipeline with AWS. It is a very powerful tool and you should be using it today to deploy.